
Кодирование информации – процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения.

Три типа кодирования которые применяются в радиотехнических системах (РТС):
- эффективное кодирование (сжатие информации) – направленное на уменьшение избыточности информации;
- помехоустойчивое кодирование (канальное кодирование для РТС) – направленное на повышение устойчивости к частичной потери информации вследствие воздействия помех;
- криптография (кодирование с засекречиванием информации) – направленное на защиту информации от несанкционированного доступа.
Структура РТСПИ с учетом кодирования
В схеме передачи сообщений представлены все виды кодирования и соответствующие им кодирующие устройства на передающей стороне (кодеры) и декодирующие устройства на приемной стороне (декодеры).

Эффективное кодирование – процесс уменьшения избыточности информации (сжатие информации).
Смотрим на рисунок изображенный выше. Есть блок эффективное кодирование, который устраняет избыточность информации. Обычно сообщение, речь, изображение, видео, любая информация, которую мы воспринимаем из внешнего мира, вносит большую избыточность. Чтобы уменьшить избыточность, применяют сжатие.
Если не применять сжатие, тогда понадобится гораздо большая пропускная способность канала связи.
Если есть такая необходимость применяется помехоустойчивое кодирование, т.е. шифрование. Если привести в пример мобильную связь, то там шифрование играет важную роль, если бы его не было, тогда наши разговоры были бы слышны всем. Без помехоустойчивого кодирования не работает ни одна РТС, которая передает цифровые сообщения.
Помехоустойчивое кодирование располагается перед модулятором, предназначено для устранения ошибок в канале связи. На этом этапе добавляется избыточная информация. Если не добавлять избыточности, тогда нельзя исправить ошибки.
Приемное устройство состоит из демодулятора, помехоустойчивого декодера, криптографического декодера, эффективного декодера. Сначала устраняем ошибки, затем дешифруем и разжимаем информацию, чтобы можно было воспринимать информацию.
Эффективное кодирование
Пропускная способность это ширина спектра, чем больше пропускная способность, тем быстрее передается информация и тем шире становится спектр, чем шире спектр становится, тем меньше каналов в эфире можно расположить.
Эффективное кодирование бывает:
- сжатие без потери информации — наиболее применим для сжатия текста, файлов и т.п, где потеря информации недопустима;
- сжатие с потерей – наиболее применима для сжатия аудио, речи, изображения, видео и т.п.
Если при передаче информации, мы не можем позволить себе потерять даже один бит, тогда, нужно сжимать и разжимать таким образом, чтобы разжатый файл полностью повторял то, что сжали.
Если работать с той информацией, которую можно немного исказить, то будет достигнуто лучшее сжатие. Такое сжатие применимо в аудио, сжатии речи, изображение, видео. Идет размен между степенью сжатия и качеством, но по прежнему, например картинка или звук сохранили свою информативность.
Рассмотрим пример 1:
Есть несжатая звуковая информация разрядностью 16 бит, и частотой дискретизации 44100Гц имеет скорость 705 кБит/с. Для речи достаточно частоты дискретизации 8кГц, 16бит≈128кБит/с.
В таблице представлены скорости, которые обеспечивают речевые кодеки.

Можно битовую скорость уменьшить на несколько порядков. Это сжатие с частичной потерей информации, разборчивость плохая, но она все же будет.
Пример 2:
Формат передачи видео PAL и SECAM без сжатия потребовал бы информационной скорости ≈ 249 МБит/с (720×576× (3×8) × 25). Со сжатием MPEG-2 информационная скорость составляет порядка 15 Мбит/с.
Сжатие без потери информации
При сжатии текстовых и файловых сообщений необходимо сжатие без потерь. Как можно сжать информацию, чтобы объем информации уменьшился, а сама информация не терялась?
Рассмотрим на примере алфавита. Чем буква встречается чаще, тем меньше информации она в себе несет и наоборот.
Суть сжатия без потерь заключается в том, чтобы тем символом который встречается часто присваивать короткие кодовые слова. Но тем, которые встречаются редко, можно присвоить и по длиннее кодовые слова.
Например, кодируем русский алфавит, кириллицу. Объединим буквы е и ё, тогда 32 буквы. Потребуется 5 бит, чтобы закодировать 32 различных символа. 2^5=32. Сжимаем на основании того, что какие-то буквы встречаются редко, а какие-то часто.
Оптимальный код сжатия должен учитывать вероятность появления символа, буквы. Таковым кодом является код Хаффмана.
Каким-то буквам поставим 3 бита, которые часто встречаются, Буквы, которые редко встречаются, им можно поставить 9 бит. Но нас интересует не одна буква, а текст. Для примера посмотрите табличку.
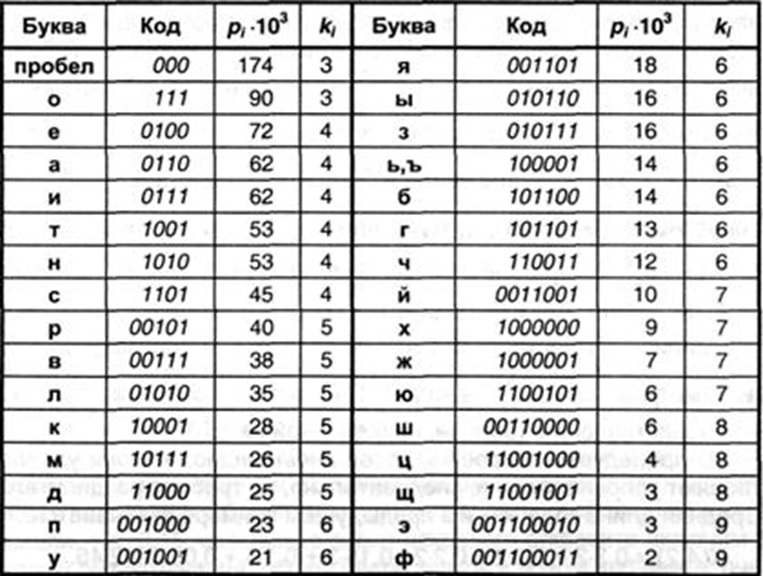
Чем больше вероятность, тем чаще буква встречается. Тем меньше кодовое слово. Несмотря на то, что часть символов имеют длину кодового слова больше, чем если кодировать напрямую, все равно, за счет тех символов, которые встречаются в среднем объем информации станет меньше.
Код Хаффмана применяется в любом сжатии, изображения, звук, только там в качестве символов не буквы, как мы рассмотрели пример, а паттерны.
ИТОГ: Сжатие без потери информации осуществляется за счет того что, те символы, которые применяются часто, им ставятся короткие кодовые слова, а которые редко, там можно ставить длинные кодовые слова.




